This article attempts to provide a brief introduction to the co-occurrence matrix and its implementation in python.
Given a document with a set of sentences in it, the co-occurrence matrix is a matrix form of representation of this document. To core idea of the co-occurrence matrix is to check if a particular word appears in the context of a focus word.
Let us take an example to understand this better. Let us consider a document containing two sentences S1 and S2 as shown in Figure 1.

There are three parts to creating a co-occurrence matrix. They are:
- Matrix of unique words
- Focus word
- Window length
Matrix of unique words
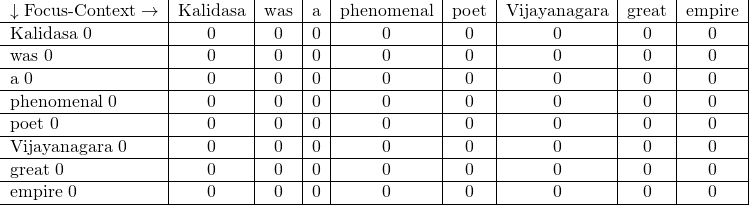
Let us create a matrix of all the unique words in the document as shown in Figure 2. All the values in the table are initialized to 0.

Focus word & Window Length
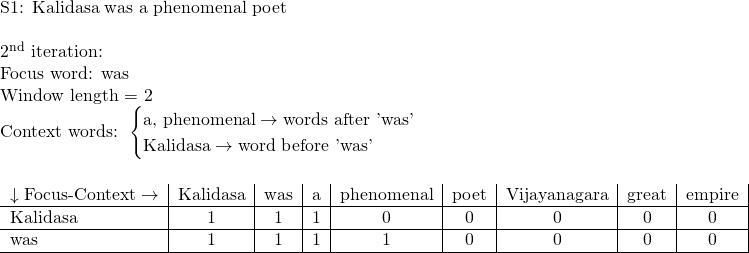
Once the matrix is created, we scan through each word (focus word) of each sentence of the document. We also determine the window length. This is the number of words we are considering, around the focus word. These are our context words.
Our objective is to identify the number of context words for each focus word in the document for the given window length. The same process is elaborated in Figure 3.


Since the words ‘was’ and ‘a’ appear in the context of the word ‘Kalidasa’, the columns corresponding to ‘was’ and ‘a’ across the Focus word ‘Kalidasa’ in the table shown in Figure 2, is incremented by 1 as shown in Figure 4.

Since every focus word appears in its own context, all the diagonal elements are incremented. Hence, the column ‘Kalidasa’ is also incremented. Continuing the process as shown in Figure 5.

Upon doing this process for all the words in S1 and S2 we get the following matrix as shown in Figure 6.

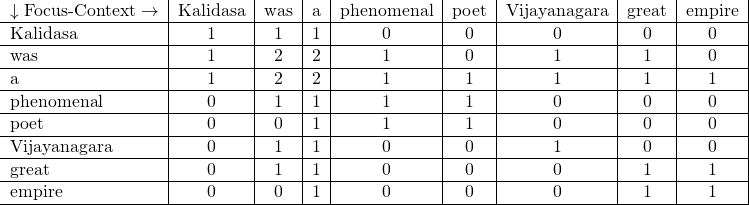
In this way, the co-occurrence matrix can be created which can later be used for analysis.
Improvements
In the current co-occurrence matrix, the stopwords are being included. This would unnecessarily increase the size of the matrix and also increase the computational cost. The size of the matrix and the computational cost can be reduced by:
- Removing the stopwords in the document
- Considering only the important words in the co-occurrence matrix using TFIDF vectorizer
Comments
Post a Comment